Rilasciato DistroClone 1.3.4 DistroClone si aggiorna alla versione 1.3.4 con un fix critico che bloccava l’intero...
Github

DistroClone – Crea la tua Live ISO da un sistema Debian in esecuzione DistroClone Live...
Yt2md Converter YouTube to Markdown Nel corso dello sviluppo di vari progetti open source, mi...
Advanced Comics Converter CBZ/CBR in PDF Introduzione Advanced Comics Converter (ACC) è un potente strumento professionale...

Convertire cbr cbz pdf con Comics Converter Questo mio script Bash, denominato Comics Converter, è progettato...

Cisco packet tracer su SysLinuxOS 13 e Debian 13 Packet Tracer è già presente...
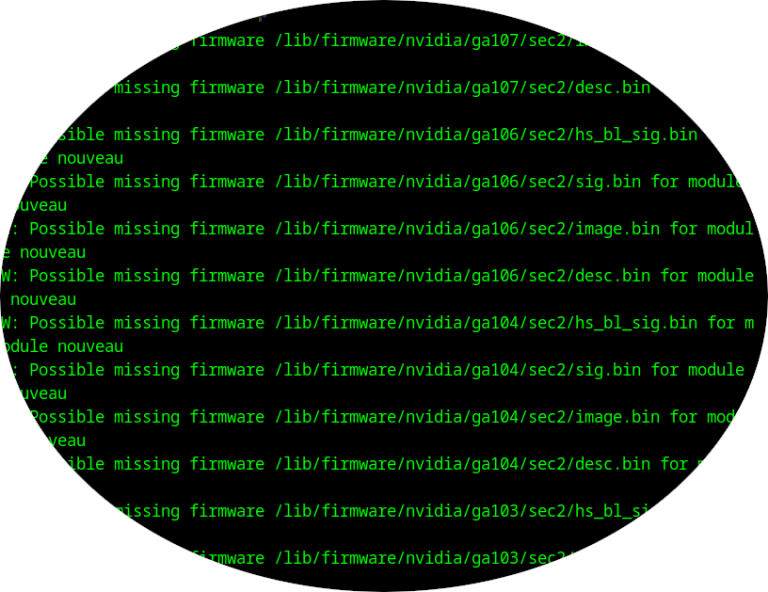
Fix Possible missing firmware /lib/firmware/nvidia Questo errore si presenta quando si aggiorna il kernel, e...
Cambiare nome interfaccia di rete a eth0 su Debian 12 Guida su come cambiare il nome...

Convertire Fumetti Cbr/Cbz in Pdf con AllCbrztoPdf Uno dei problemi più comuni che gli utenti devono affrontare...
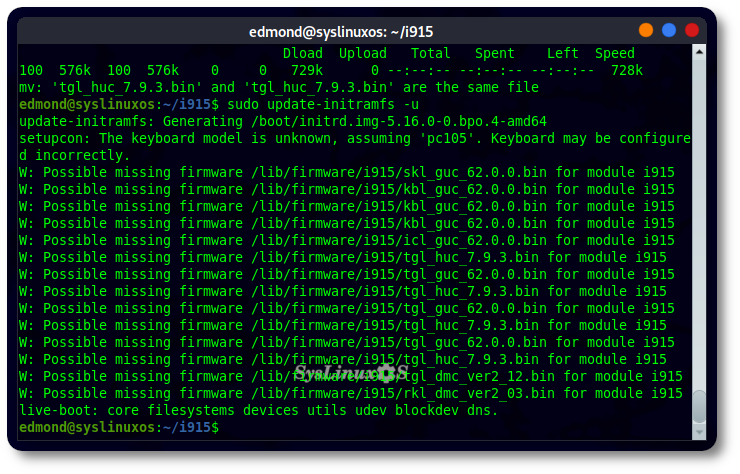
Fix error Possible missing firmware /lib/firmware/i915 Questi tipo di errori sono presente oramai da qualche...