
Advanced Comics Converter CBZ/CBR in PDF Introduzione Advanced Comics Converter (ACC) è un potente strumento professionale...
Tv-Multimedia

RCU – Rename Comics Universal. Hai una collezione di fumetti digitali in disordine? Rename Comics Universal...

Convertire cbr cbz pdf con Comics Converter Questo mio script Bash, denominato Comics Converter, è progettato...
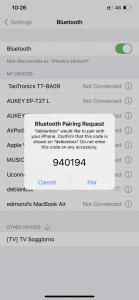
Guida su come ascoltare la musica presente nel telefono, tramite bluetooth, direttamente da un pc/notebook. Con...

OpenMediaVault su Raspberry Pi 4 Guida su come installare OpenMediaVault su Raspberry Pi 4, con...

Trasformare un Libro da pdf in AudioLibro A volte può risultare utile trasformare un file pdf...
Per installare FFmpeg su Debian Jessie bisogna inserire i repository multimedia. Su questo blog c'è...
Per installare Skype 64bit su Debian Wheezy, bisogna abilitare prima il supporto al Multi-Arch. e...
Guardare e registare SkyTg24 usando mplayer e vlc: # apt-get install rtmpdump ...
Io principalmente per la tv digitale uso Vlc, in seconda battuta uso MeTv e Kaffeine. In...
Il titolo del post non lascia spazio a dubbi, riuscire ad aumentare la risoluzione del...
Convertire video mp4 in avi senza perdere in qualita, con il solito FFmpeg. $ ffmpeg...
Convertire un video ogv in avi, usando mencoder. Di solito l'estensione ogv si trova quando...
Convertire video da AVI a WebM usando il solito FFmpeg. Nel caso specifico essendo su Debian...



